
Optimizing Relational Databases: Strategies and Techniques
Optimizing and Scaling Relational Databases is crucial for enhancing query performance and ensuring efficient data management. This comprehensive guide explores various optimization techniques that database administrators and developers can employ to improve the functionality of relational databases.
Indexes: Accelerating Data Retrieval
Primary and Secondary Indexes
Indexes are vital in speeding up data retrieval operations in databases. A primary index, created on a table’s primary key, quickly locates specific rows, while a secondary index, on non-primary key columns, enhances the performance of queries involving those columns.
B+ Trees: The Backbone of Indexing
B+ trees are widely used for efficient indexing. They are self-balancing tree structures that store data in a sorted manner, facilitating fast data retrieval and efficient query processing. Internal nodes guide the search, while leaf nodes contain the actual data or pointers.
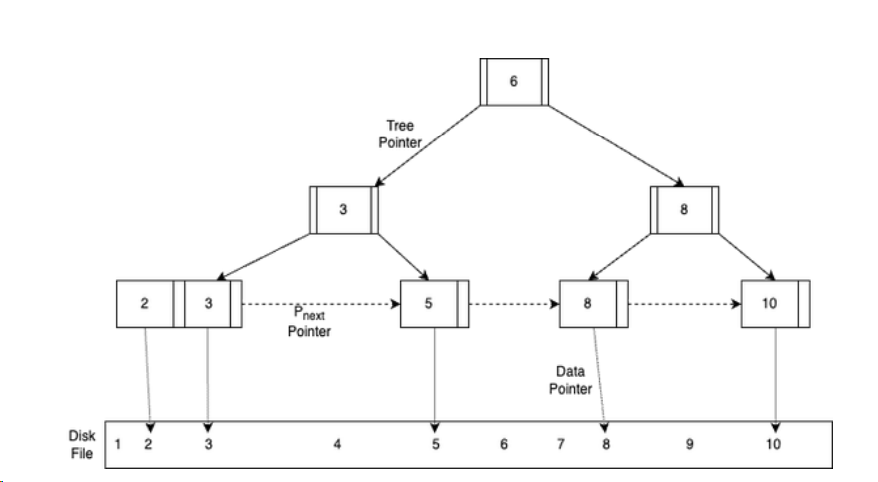
B+ tree data structure
Efficiency in Different Queries
B+ trees excel in key-based searching, range queries, sequential and range scans, and efficiently handle updates and insert operations. However, excessive indexing can increase space requirements and slow down writes.
SQL Tuning: Refining Query Performance
Benchmarking and Profiling
Benchmarking under high-load situations and profiling to analyze slow query logs are essential first steps in SQL tuning. This process uncovers bottlenecks and optimizes query plans.
Minimizing Large Write Operations
Optimizing SQL performance involves minimizing extensive write operations, which can impact performance and lead to table blocking. Scheduling heavy queries during off-peak hours and employing techniques like JOIN elimination can significantly enhance query efficiency.
Denormalization: Balancing Read and Write Performance
Denormalization improves read performance by duplicating data across tables, thus avoiding complex joins. While beneficial for read-heavy workloads, it introduces data redundancy and complexity in maintaining consistency.
Query Federation: Distributing the Load
Query federation involves splitting a large query into smaller ones executed on different servers. This technique reduces overall execution time and is especially effective for queries involving large datasets or complex joins.
Optimizing relational databases is a multifaceted task requiring careful consideration of indexing strategies, SQL tuning, denormalization, and query federation. By effectively employing these techniques, database administrators can enhance performance, ensuring faster and more efficient data access. In the next section, we will explore practical techniques for scaling relational databases, including partitioning, sharding, and replication.
Scaling Relational Databases
In the ever-evolving world of data management, scaling relational databases is a pivotal task for businesses grappling with growing data needs. Scaling, in this context, refers to augmenting a database’s capacity to handle more data, users, and transactions. Central to this endeavor are techniques like partitioning, which we will explore in detail.
Partitioning: Dividing to Conquer
Partitioning is about splitting a large database table into more manageable segments called partitions. This division ensures efficient data organization and query processing. The partitions can function independently, allowing for focused or distributed query handling. Partitioning can be vertical or horizontal, each with its unique approach to data division.
Vertical Partitioning: Splitting by Columns
– Concept: This involves dividing a table based on columns. For instance, a customer table might be separated into two tables: one holding customer information and the other containing contact details.
– Benefits: Vertical partitioning helps isolate different types of data, potentially reducing I/O load during queries if only a subset of data is frequently accessed.
Horizontal Partitioning: Splitting by Rows
– Approach: Here, a table is split based on rows. For example, customer records might be divided into partitions based on last names or zip codes.
– Subtypes: Horizontal partitioning includes hash partitioning and range partitioning, each suitable for different scenarios.
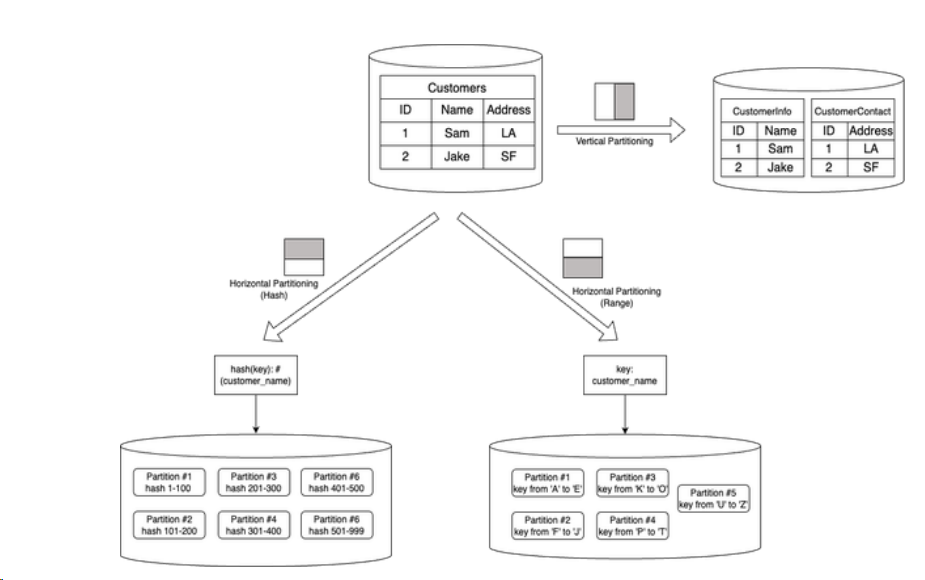
Vertical & Horizontal partitioning
Hash Partitioning
– Methodology: Involves distributing data evenly across partitions using a hash function applied to a key. Each hash value gets assign to a specific partition.
– Advantages: This approach prevents data skew and eliminates hot spots.
– Limitations: Not suitable for range queries due to its nature of distributing data based on hash values.
Range Partitioning
– Concept: Data is segmented into buckets based on key ranges, which can be continuous or discrete.
– Key Feature: Keys within each partition are stored in sorted order, enhancing range scan queries efficiency.
– Benefit: Simplifies data retrieval within specific key ranges and is relatively straightforward to implement.
– Challenge: Can lead to uneven data distribution or hot spots if not managed carefully.
Advantages of Partitioning
Partitioning offers significant benefits for handling large datasets and achieving high throughput. By distributing data across multiple machines (sharding), it handles datasets beyond the capacity of a single machine. This approach enables parallel processing of read and write queries, enhancing the database’s overall throughput and query performance.
Potential Pitfalls
However, partitioning isn’t without its challenges. If partitions are unevenly access, it can lead to skewed partitions and hot spots, where certain partitions bear a disproportionate workload, leading to congestion and performance bottlenecks.
Optimizing Partitioning
To optimize partitioning, it’s crucial to:
– Understand the data access patterns and distribute data to minimize hot spots.
– Regularly monitor and potentially re-partition data to balance loads.
– Choose the right partitioning strategy based on the specific use case and query patterns.
Conclusion:
Partitioning in relational databases is a potent tool for managing growing data challenges and is integral to Scaling Relational Databases, a core aspect of data system design. By strategically segmenting data, it not only enhances query performance but also paves the way for efficient database scaling, ensuring that systems can accommodate increasing data volumes without sacrificing performance. As businesses continue to expand, mastering partitioning will be crucial in maintaining efficient, scalable, and high-performing database systems that can grow seamlessly alongside evolving business needs and data demands.
Do you like to read more educational content? Read our blogs at Cloudastra Technologies or contact us for business enquiry at Cloudastra Contact Us.