
Introduction
Ensuring data quality and correctness in large-scale data processing pipelines is essential. In PySpark, writing transformation logic for big data can be complex, making unit testing a crucial part of the development process. However, due to PySpark’s concise APIs, developers often neglect writing tests.
Unit testing in PySpark helps validate data transformations, detect regressions, and maintain code reliability. This blog explores the importance of unit testing in PySpark and how to use Pytest to write effective tests for your data pipelines.
1. Importance of Unit Testing in PySpark
Unit testing PySpark code is necessary to ensure that data transformations work as expected. Let’s understand its significance with an example:
Imagine you are working on a PySpark project that processes customer transactions for an e-commerce platform. Your task is to calculate total revenue per customer, which involves filtering, aggregations, and joins across multiple datasets. A small logic error can lead to incorrect financial reports, affecting business decisions.
2. Why You Need Unit Testing?
Data Quality Assurance: Unit tests verify that transformations yield the expected results. For instance, tests can check that revenue values are always positive and that no null values appear in the processed data.
Regression Detection: Over time, transformation logic evolves. Unit tests serve as a safety net, preventing unexpected regressions when changes are introduced.
Handling Edge Cases: Edge cases, such as a customer without a purchase history or an unexpected spike in data volume, need to be tested to prevent failures in production.
Complex Business Logic: In real-world scenarios, transformation logic can become quite complex. Unit tests allow you to break down this complexity into testable components, ensuring that each part of the transformation works as intended.
Maintainability: Well-structured unit tests can serve as documentation for your code. They make it easier for new team members to understand the intended behavior of your transformations and how they fit into the larger data processing pipeline.
Cost-Effective Debugging: Catching issues early in the development cycle is far more cost-effective than fixing them after deployment, reducing potential financial and reputational risks.
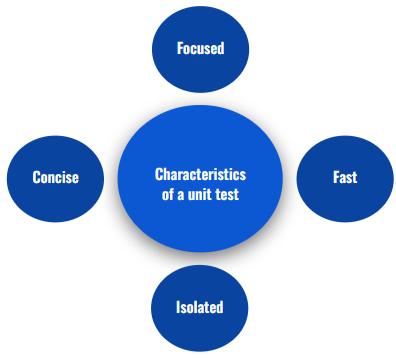
3. Characteristics of a Good Unit Test
Focused: Each test should test a single behavior/functionality.
Fast: The test must allow iteration and share feedback quickly.
Isolated: Each test should be responsible for testing a specific functionality and must not depend on external factors in order to run successfully.
Concise: Creating a test shouldn’t include lots of boilerplate code to mock/create complex objects in order for the test to run.
4. Writing Unit Tests with Pytest
Pytest is an open-source testing framework for Python that simplifies and enhances the process of writing and running tests, making it easier to ensure the quality and correctness of Python code. When it comes to writing unit tests for PySpark pipelines, writing focused, fast, isolated, and concise tests can be challenging.
Some of the standout features of Pytest:
Writing tests in Pytest is less verbose.
Provides great support for fixtures (including reusable fixtures with parameterization).
Has great debugging support with contexts.
Makes parallel/distributed running of tests easy.
Has well-thought-out command-line options.
Spark supports a local mode that creates a cluster on your box that makes it easy to unit test. To run Spark in local mode, you typically need to set up a SparkSession in your test script and configure it to run in local mode.
Let’s start by writing a unit test for the following simple transformation function!
5. Setting Up a Spark Session for Testing
To test this function, we need a spark_session fixture. A test fixture is a fixed state of a set of objects that can be used as a consistent baseline for running tests. We’ll create a local mode SparkContext and decorate it with a Pytest fixture:
“`python
@pytest.fixture(scope=”session”)
def spark_session():
spark = SparkSession.builder \
.appName(“Unit Test”) \
.master(“local”) \
.getOrCreate()
yield spark
spark.stop()
“`
Creating a Spark Session (even in local mode) takes time, so we want to reuse it. The scope=session argument does exactly that, allowing reusing the context for all tests in the session. One can also set the scope=module to get a fresh context for tests in a module.
Now, the Spark Session can be used to write a unit test for the transformation function:
“`python
def test_transformation(spark_session):
input_data = [(“customer_1”, 100), (“customer_2”, 200)]
df = spark_session.createDataFrame(input_data, [“customer”, “revenue”])
transformed_df = your_transformation_function(df)
assert transformed_df.filter(transformed_df.revenue >= 0).count() == 2
“`
6. Writing a Unit Test for a Transformation Function
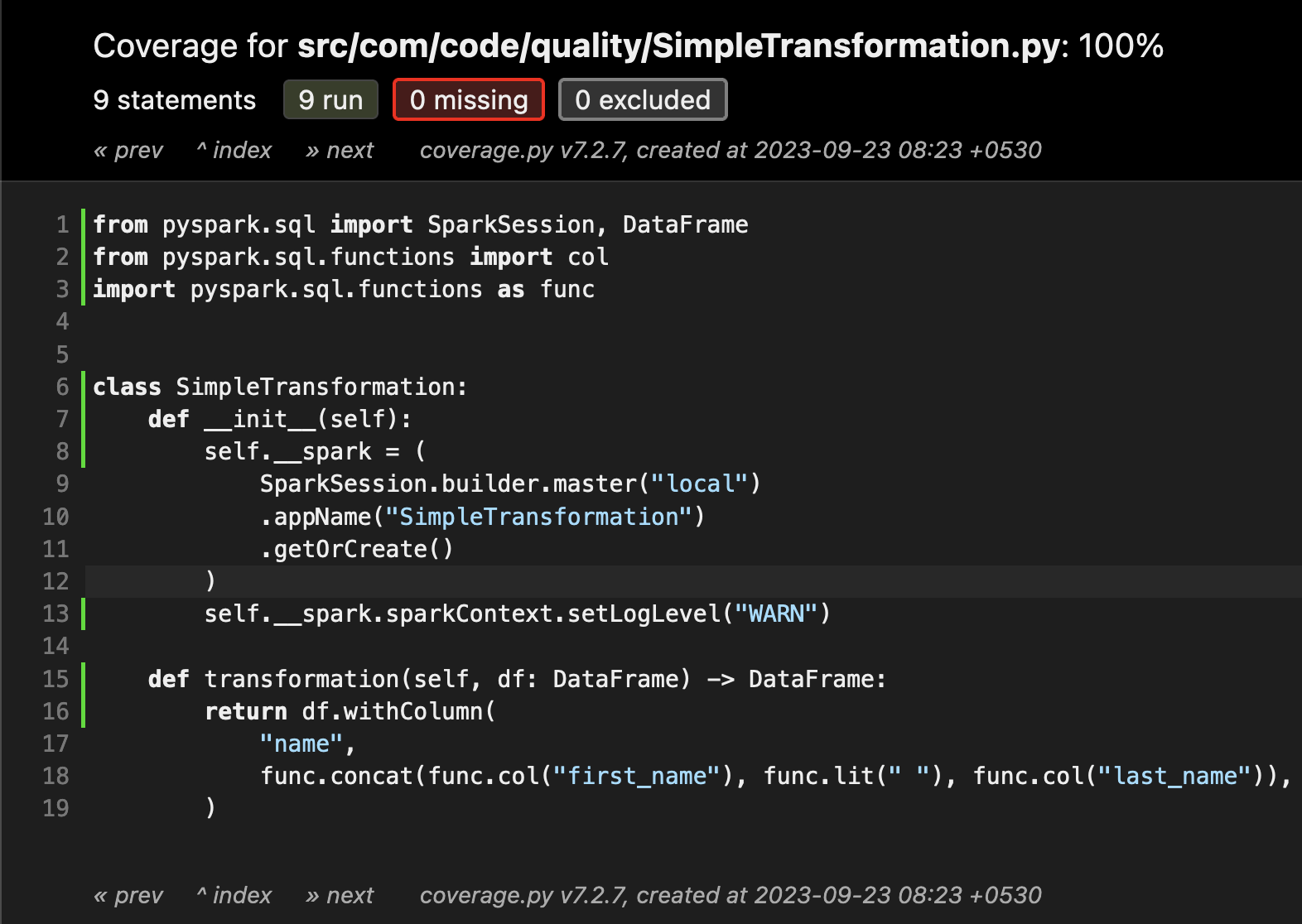
We can run the test using the following command, and it will generate the coverage report in the mentioned directory:
“`bash
python3 -m pytest –cov –cov-report=html:coverage_report tests/com/code/quality/test_simple_transformation.py
“`
By leveraging PySpark for data processing and Pytest for testing, Cloudastra Technologies offers comprehensive solutions that enhance data quality and reliability, ensuring your data pipelines are robust and effective.
Conclusion
Unit testing in PySpark is essential for maintaining data integrity, debugging efficiently, and ensuring high-quality data processing pipelines. By using Pytest, developers can create structured, maintainable, and reliable tests to validate their transformation logic.
Additionally, for organizations handling large-scale data processing, integrating AWS EMR (Elastic MapReduce) with PySpark can further optimize workflows. Unlocking Big Data Potentials with AWS EMR, combined with robust unit testing, enhances the efficiency and reliability of data pipelines, ensuring seamless analytics and insights.
By implementing unit tests in your PySpark projects, you can minimize unexpected failures, improve development agility, and maintain consistent data quality over time.
Do you like to read more educational content? Read our blogs at Cloudastra Technologies or contact us for business enquiry at Cloudastra Contact Us.